data imputation
The aim of data imputation is to impute missing data in a data set.
Classifications of the imputation methods
- categorical or not categorical data for the missing attributes or the observed ones
- functional imputation or not
Algorithms
MICE : Multivariate Imputation by Chained Equations
It is an iterative algorithm looping over the variables to impute one variable at the time using a model taking as input the other variables. It loops over each variable having missing values several times (usually 10).
MICE operates under the assumption that given the variables used in the imputation procedure, the missing data are Missing At Random (MAR). MICE does not offer a guaranty of convergence.
Expectation-maximization and data augmentation
GAIN
It is based on a neuron network model.
VAE
It is based on auto encoder neuron network model.
PMM
It works from one missed ordinal attribute like KNN but taking the most frequent value in the neighborhood.
Decision tree with distribution as leaves
In scikit-learn, DecisionTreeClassifier the predictproba method can be used for implementing this.
A good properties of decision tree is that they are able to avoid some attributes based on some conditions (see Adult dataset, below).
Drawbacks :
- it does take into account the missingness of variable to obtain the distribution, so MNAR cases can not be tackle efficiently
- in DBLP:journals/csda/DooveBD14, during the split, variable selection is biased in favour of variables with certain characterics (e.g. variable with many categories), if these variables are no more informative than the competitors.
- it is univariate
- Decision trees tend to overfit on data a large number of variables (source)
Implementations
- no implementation of tree classifier for categorical data in scikit learn : https://github.com/scikit-learn/scikit-learn/issues/5442
building a BID
Datasets
Adult
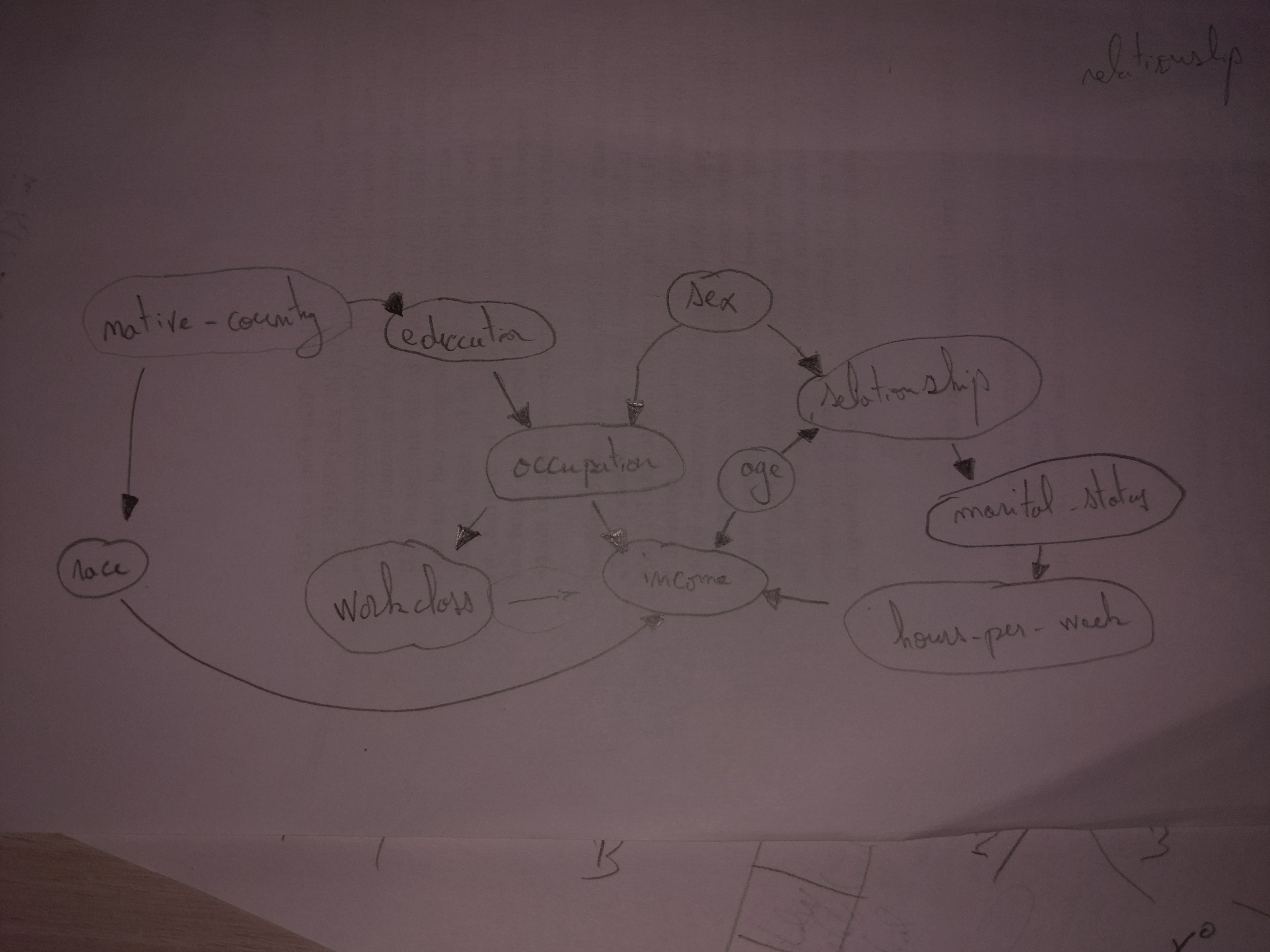
https://archive.ics.uci.edu/dataset/2/adult
It is a dataset with mostly categorical attributes, with no duplicate in the tuples.
{kind=link}